Many of you, I suppose, tryied or are already actively using or looking at the model of storing and publishing documentation as code, which means applying all the same rules, tools, and procedures to documentation as to program code, such as storing in a repository, running tests, and building and releasing in CI/CD. This approach keeps the documentation up to date with the code, versioning, and tracking changes using familiar development tools.
At the same time, many companies have also had wiki systems for years where other teams and employees, such as project managers, write, review, discuss, and read documentation. What if I tell you you can to bring storage and publication into a single view, which means publish docs in Confluence using docs-as-code pipeline?
In this post, I’ll give an overview of solutions which can help publishing documents from a repository to Confluence.
One solution I’d been actively using for a long time myself (RST+Sphinx+sphinxcontribbuilder), while I was working in the UI development team, and the others I will present as an alternative. I should point out right away that I haven’t tried them in practice, just studied the configuration process and capabilities.
Sphinx doc+sphinxcontribbuilder
Sphinx (not to be confused with the popular search index) is a static generator written in Python and actively used by the community, it works quite well in other environments as well.
I won’t explain how to start using it, only say that out of the box it can generate static HTML, man, pdf and a few other formats, but in order to build and publish it correctly the repository should have files index.rst (main page layout), conf.py (configuration file) and Makefile (file description of the format generation,
it can be placed into docker and run sphinx-build command there).
Out of the box Sphinx can generate docs from lightweight *.rst (RestructuredText) markup, but we in the project added also an ability to write in Markdown for those developers who find it more convenient (we used m2r extension which converts MD to RST).
We already had the whole Sphinx docs environment set up and documentation builds crammed into a separate staging in Jenkins’ pipeline, so we went ahead and used the sphinxcontrib.confluencebuilder extension which can build docs in a native Confluence format and then publish them.
Confluence in this case is one of the output formats for docs, along with HTML.

To make this work, you need to specify the extensions in conf.py, below is a configuration snippet example.
extensions = [
'sphinxcontrib.confluencebuilder',
'm2r'
]
templates_path = ['_templates']
source_suffix = ['.rst', '.md']
master_doc = 'index'
exclude_patterns = [
u'docs/warning-plate.rst',
u'FEATURE.md',
u'CHANGELOG.md',
u'builder/README.md'
]
And then configure the extension, it has a set of settings:
confluence_publish = True
# switch off/on publishing to Confluence
confluence_space_name = 'YOURSPACEKEY'
# the space to publish to from the repository
confluence_parent_page = 'Raw Documentation'
# the parent page, can be a space's home page
confluence_server_url/confluence_cloud_url = 'https://yourconfluence.site.net/'
# your Confluence host name
confluence_publish_prefix = 'WIP-'
# prefix to add before the page titles, to ensure they're unique
confluence_publish_postfix = '-postfix'
# postfix to add after the title
confluence_header/footer_file
# a path to file to include on top and on the bottom (we use include from other pages, for example, to insert a warning block which asks not to edit page manually)
confluence_page_hierarchy = True
# if in the master doc there is a TOC, documents listed in it will be listed as child docs of this document
confluence_purge
# deletes all pages that are not released in a current publishing cycle, this is convenient if you always publish all pages or change titles, but use it wisely - it recursively deletes all the pages in the specified folder
confluence_remove_title
# remove duplicated title
confluence_publish_subset
# specify a list of docs to publish
confluence_max_doc_depth
# maximal child pages depth to publish as separate pages, not sections
confluence_prev_next_buttons_location = 'top'
# where to place Previous-Next buttons
confluence_server_user = os.getenv("CONFLUENCE_USERNAME", "confluence-bot")
confluence_server_pass = os.getenv("CONFLUENCE_PASSWORD", "")
target = os.getenv("TARGET", "")
if target == "CONFLUENCE":
confluence_publish_prefix = ''
confluence_parent_page = 'Your Space'
#this allows to publish docs from a local repo into a separate folder to review them first, we mark them as WIP-
The important point is that even if the page (source in .rst) is not specified in toc and not added to exclude_patterns, it will still be published but outside the hierarchy. Page titles in Confluence will correspond to the first title of the page, for example, if you have the Example title in example.rst file underlined with equals will become the page title in Confluence.
A rule of a thumb is, create a bot with the authorization data on behalf of which you will publish documents, you can pass them as environment variables in docker compose, use them in pipelines.
Of course, there are pitfalls as well. First, not all RST syntax is supported for publishing to Confluence (╯°□°)╯︵ ┻━┻), it’s not convenient if you want to build HTML and Confluence from the same source. It does not support container and hlist directives, almost all directive attributes, such as highlighting lines in the code block, numbering in the table of contents, alignment and width for listtable. The list of what is supported is still pretty good.
The good news is that includes is supported, it allows to reuse content snippets between different documents, autodoc for building documentation from code, math for mathematical formulas, rendering of tickets and filters from jira (for that you should also add Jira server to the configuration), numbered headers and much more, they are constantly releasing updates.
By the way, Jira support has also appeared in the Pandoc multi-converter, since version 2.7.3 Pandoc has supported the corresponding confluence wiki markup.
For those Confluence macros and elements that are not supported, there is a dirty hack. RST has directive ... raw::, and it has attribute confluence, it accepts conf markup,
if you really need some macro - you can copy it in page editing mode in Confluence (source mode is available by <> icon) and paste its “raw” code there. But I didn’t teach you that.
.. raw:: confluence
<ac:structured-macro ac:macro-id="c38bab13-b51e-4129-85ef-737eab8a1c47" ac:name="status" ac:schema-version="1">
<ac:parameter ac:name="colour">Green</ac:parameter>
<ac:parameter ac:name="title">Is used</ac:parameter>
</ac:structured-macro>

Why did we need to set up publishing from the local repository to a test page, and not directly to an “inline” page? The point is that when publishing, all pages are republished each time and overwritten changes made manually or inline comments. So, when a document is in progress, we decided to publish it to a separate page, as a kind of staging mode, to add published versions to the review and collect comments.
On CI publishing is implemented as a separate template in Jenkins’ pipeline and inside this template, we have run a docker image on a remote registry which implements a sphinx-build with the desired configuration. It is better to skip this step right away.
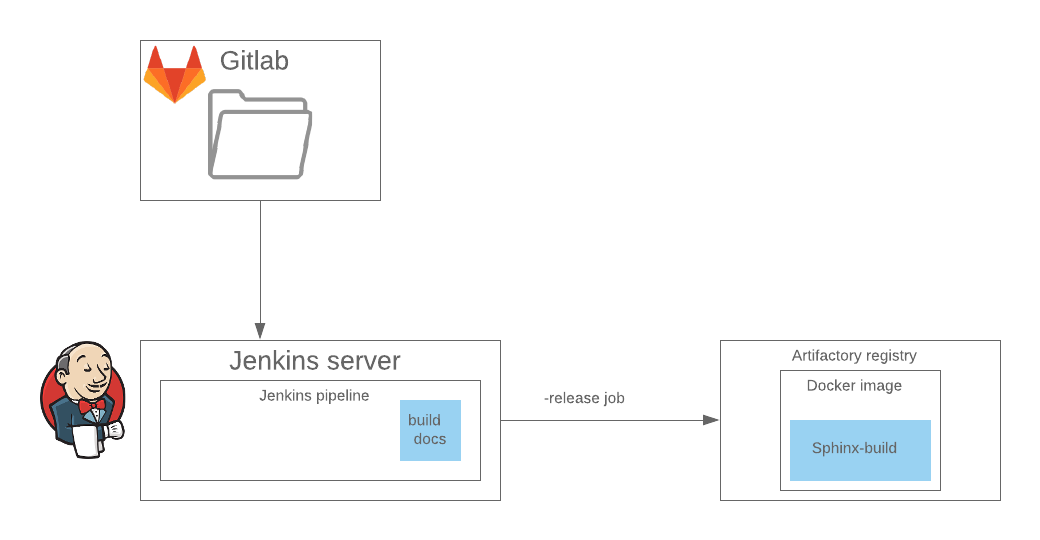
pipeline {
agent {
label "${AGENT_LABEL}"
}
stage("Documentation") {
steps { ansiColor('xterm') {
withCredentials([usernamePassword(
credentialsId: "${DOCUMENTATION_BOT}",
usernameVariable: 'CONFLUENCE_USERNAME',
passwordVariable: 'CONFLUENCE_PASSWORD'
)]) {
sh "docker-compose -p $COMPOSE_ID run sphinx-doc confluence"
}
}}
}
Inside the stage, in fact, the docker-compose -p release-branch-name run sphinx-doc confluence is being run.
In turn, Jenkinsfile describes the dependencies and environment in which the step will run, the process of building and updating the information in the target. Of the tests so far there is only checking the .md and .rst syntax with doc8 and markdownlinter.
One more important thing to know: every time you publish a subset of pages, Sphinx updates the whole tree, every page. That is, even if the content has not changed, a change is created, if you have notifications set up in the feed, it will get clogged with lots of notifications.
A few more ways to do the same
Foliant with Confluence as the backend
Foliant is a documentation generation tool with Mkdocs and lots of preprocessors under the hood and a backend in the form of Confluence. You can read more here, but in brief, it uses Pandoc to convert MD to HTML and then publishes it to Confluence. You just need to configure the backend and install pandoc in the environment as a dependency.
Advantageous differences from the first solution: it knows how to restore inline comments in the same places as they were before the page was republished, allows you to create pages by setting them in config, edit their names, and insert content inside an existing page, for this you need to manually set foliant anchor on the page in Confluence.
Only works with Markdown source.
Metro
A multi-tool that publishes a variety of source formats in Confluence, from Google Docs to Salesforce Quip, and can also publish to Markdown.
To publish, you need to put the file manifest.json in the folder where your .md files are located, specify the folder,
the file to be published, for each file specify confluence page id. The name of the page will be the first header in the file (#). This tool has a bit of a twist with Markdown markup.
Read more in the docs.
Attachments and pictures should be placed in the same folder, and the tool also allows you to specify the use of the table of contents directly in the config.
Gem md2conf
Ruby gem md2conf, which converts Markdown to native Confluence XHTML.
Next, you can write a Rake task, which in turn can be called via Gitlab CI/Jenkins by push to master,
then pull the Confluence API to publish the page.
To keep your Ruby environment clean, wrap the dependencies for this gem in a container.
How to send requests to the Confluence API is described here.
It works only with Markdown source.
What else I’ve found on Github
There are already a lot of such scripts or cli-tools in the community, but I only experimented with md2conf, all of them are divided into two groups.
- Those that just convert formats (md, asciidoc, rst -> confluence/xhtml):
- markdown2confluence
- md2confluence
- jedi4ever/markdown2confluence
- There’s even a web-service with a UI to convert between md and Confluence.
The most elaborate one I’ve seen is this one (https://github.com/rogerwelin/markdown2confluence-server). The author wrote a Dockerfile, which raises the cli-instrument as a REST server and then you can send a bunch of conversion requests to it.
- And the ones that immediately implement in themselves and requests to Confluence API, you only need to specify the API key in the config:
Choose any of the options (depending on your markup language and stack) and build your Pipeline depending on the tasks you have in front of you.